
GenAI - Setting Expectations
GitHub ·So! You’re either evaluating or have started using a generative AI tool for your work. Or you’ve just heard everyone talk about how amazing ChatGPT is and you’re sick of it. If you wanted to use a generative AI tool, how are you supposed to use it exactly? Should you even be using a tool for ___ task?
I’ve been having discussions about generative AI A LOT recently. I’m a Solutions Engineer at GitHub, and that means I get to work with customers as they’re evaluating GitHub Copilot. If you’re not familiar, we’re explaining it as an AI pair programmer that will help developers write better code faster. My experience has mostly been with GitHub Copilot, but I think what I’m going to discuss today applies to any type of generative AI. I’ve played with Bard, Bing AI, and some image generation ones (Canva AI). I’ll call out any caveats if necessary.
I might make follow up posts on this one because this technology is so new, has had a ton of buzz, and is rapidly evolving. But what my goal is here is to give a clearer picture on what I think you should be expecting with GenAI - either as a decision maker or a user of it in the professional sense. I’ve learned a lot talking to people I consider leaders on the subject (@ryanjsalva, Matt Gunther, ..) but these opinions are my own.
The TLDR: GenAI is technology that is meant to make you more productive, not be perfect. It will get you a % of the way to your destination, but cannot make that journey alone. The best use cases are suggestive and not authoritative.
Let’s dive a little deeper into this.
Different applications of AI
GenAI is only one application of the AI umbrella. That’s important to remember and sometimes gets lost in the hype. AI has been around for a while in various forms and applications. From computer vision to education tailoring - these applications are bountiful and have been used to varying degrees in almost every industry. In my opinion, wherever you look with AI, you can separate its application as either:
- Suggestive
- Authoritative
- (Bonus) Mixture of both
To get my point across. Let’s look at 2 different applications of predictive machine learning: Recommendation Systems and Prediction Algorithms
Recommendation Systems
Recommendation systems, which have such a strong impact on us as individuals in the decisions we make, thing we buy, and even our social opinions are so embedded into society that we see their functionality as banal today. But this is an extremely powerful form of AI - if not the most valuable $ wise.
The almighty “algorithm”. Whether it’s TikTok’s crazy algorithm that is able to seize the attention of anyone that spends more than a couple of minutes or Amazon’s system based on item-to-item collaborative filtering (fascinating read by the way), this is embedded in so many platform tools.
The use case of Recommendation Systems, from the end user’s perspective, is suggestive. It’s particularly useful to have the app you’re using suggest products/services from an overwhelming catalog of things you can choose from. As a business developing these systems, you are trusting your algorithm to output something (a suggestion) directly to the end user without human vetting. This suggestion is usually distilled to something simple - i.e. the product-id that is most likely to be purchased.
I consider an AI output to be suggestive especially if the risk of it’s output is low and can easily be ignored. When Amazon suggests a specific screen protector alongside a phone case, the potential damage of a user seeing that suggestion and not agreeing with it is extremely low. At worst, a wrong suggestion is mild annoyance. At best, they buy another new product. It’s low risk.
Of course, you wouldn’t want a a recommendation system that has consistently poor outputs and gets users mildly annoyed, very annoyed, and churning. But for each individual product, you are risking very little. In fact, the lack of interaction with a suggestion in itself can be used to further train the algorithm - a benefit in itself.
Keep this suggestive aspect in mind as we loop back to GenAI.
Prediction Algorithms
Recommendations Systems, mentioned above, are just one application of predictive machine learning. Using vast amounts of data to predict an output is not unique to just buying a product or watching fun videos.
Under the umbrella of AI sits predictive machine learning, and under that umbrella sits prediction algorithms. These are usually used by businesses and don’t involve creating an output for an end user to interact with. They are also higher risk.
One common example is insurance. Insurance companies (e.g. Liberty Mutual, Sun Life) have very much adopted using predictive models to determine things like the premiums charged to claimants. They will use huge amounts of data which include a variety of factors: race, gender, credit score, financial activity, and more. Determining the price of insurance for an individual, and if that person gets insurance in the first place is an authoritative application of AI. It is high risk and can have very severe impacts on both the affected individual and the business. What happens if someone is refused insurance or charged a premium they should qualify for? A high-risk decision is made by the machine and not just suggested to the individual affected.
Another example is in Finance. Banks are using prediction algorithms in the form of neural networks to automatically detect and flag charges outside the norm - with sometimes these applications going the full way and blocking credit cards/accounts of an end user based on activity. In these cases again, we see an authoritative approach. The AI application is not just determining an outcome based on a huge dataset (fraudulent vs not fraudulent charge), it can go all the way and be given permissions to make a higher risk action without human vetting. In the case where the application just flags this to an internal employee, I would consider it a suggestive approach.
There are a variety of other applications of AI, but I think this helps me get my point across. With AI/ML so far we have been able to create applications that can either suggest outputs to users which are low risk, or use these outputs to themselves perform high risk actions. So revisiting our buckets:
-
Suggestive: augment human ability by processing a ton of information, outputting a result to a person, and letting this person make a decision and take action.
-
Authoritative: bypass human input by processing information, outputting a result, and making decision/take action based on this result.
So what’s new here, where does GenAI fall?
Generative AI itself is a huge step, mainly as a new powerful application of AI. With the use of LLMs as their foundational layer, Generative AI applications are able to not only understand human input (usually using NLP in some form), but create what could be considered net new content in the form of text, images, or even video. This is huge.
Each of these modalities mentioned earlier (text, image, video, speech, etc.) are extremely complex, and objectivity of the correct “output” here is even more difficult to reliably teach a computer.
What do I mean by this? It is straightforward, albeit difficult, to teach an algorithm that a video-id should be shown next to a TikTok user. You’re basing that decision on a ton of information (video category, user details, etc.) but the output is distilled to something specific: video-id that will increase X metric (usually engagement). The potential risk of a wrong decision here is also low as mentioned earlier, as the worst case is the user just moves on to the next video and gives you more information.
Generating a legal document based on requirements passed on by an end-user is a much more difficult thing to teach an AI to do correctly in an objective manner though. And that’s not even considering the risk of the AI missing some use cases and allowing for legal loopholes or potentially putting the user in a precarious legal position. Generating content based on a provided input can be very subjective, and the impacts are far greater than other forms of AI depending on how it’s used.*
Ex Machina or word-probability machine?
If you’re not familiar with how GenAI tools like ChatGPT work, it’s a very deceptive but effective form of “intelligence”. OpenAIs LLMs that are used for apps like ChatGPT don’t really understand what is being output. When outputting a response, the LLM determines the probability of a word following another one based on the prompt. For each word being output, it is (lightning-fast) determining the next most likely word. It’s doing this on a word-by-word basis and doesn’t “understand” its output. It didn’t vet it in it’s brain to make sure it makes sense, as we humans do before speaking - or at least we should.
Generative Adversarial Networks (GANs) get around this problem somewhat. Vetting any output (or having a “check” as part of the model) is especially useful when creating image content. But not everyone is implementing these, especially when it comes to text-based content. You can read more about GANs here.
My point is this: generating content is not only subjective and a higher level of complexity than other applications of AI in the past, its impacts and risks are also immediately apparent to the end user. For these 2 reasons, GenAI’s applications today are mostly suggestive. It would not be responsible to expect it to do anything more than suggesting outputs at this time.
This will likely change in the future as we gain confidence in these LLMs, but if and when this is viable is a question I don’t have the answer to.
What to know about my suggestion machine?
Given all this background on its risks, and use cases, is it even useful? Yes, tremendously, so long as you realize what the purpose is:
GenAI today is made to make you more productive. That’s really it.
Let’s take a look at how it helps you accomplish faster:
Data Sources
GenAI will have 3 broad sources of information:
- Dataset
- Context
- Prompt
The dataset is the underlying information used to train the model. 175 billion parameters in the case of GPT-3, for example. This is the work that has already been done for you by researchers, scientists, and experts to gather a ton of information and make it available to use by the model they tuned. These are usually millions of dollars in investment.
The context is any personalized data source you can plug into the tool. Generative AI has the ability to tailor responses to your needs by giving it more info. For example the codebase you are using GitHub Copilot with, or the document you’re working on in Microsoft’s Copilots. I think we’ll see the ability to plug in data sources be made easier as the tools mature.
The prompt is how you ask the AI what to do, the instructions you pass. Prompts are the most mutable portion of this equation, and is why a lot of attention is being put into concepts like prompt engineering. Clearly communicating what you need from the tool is the best way to increase success
Microsoft did a good job at illustrating this trifecta for the M365 Copilot. With the prompt top left, context bottom left, and dataset on the right:
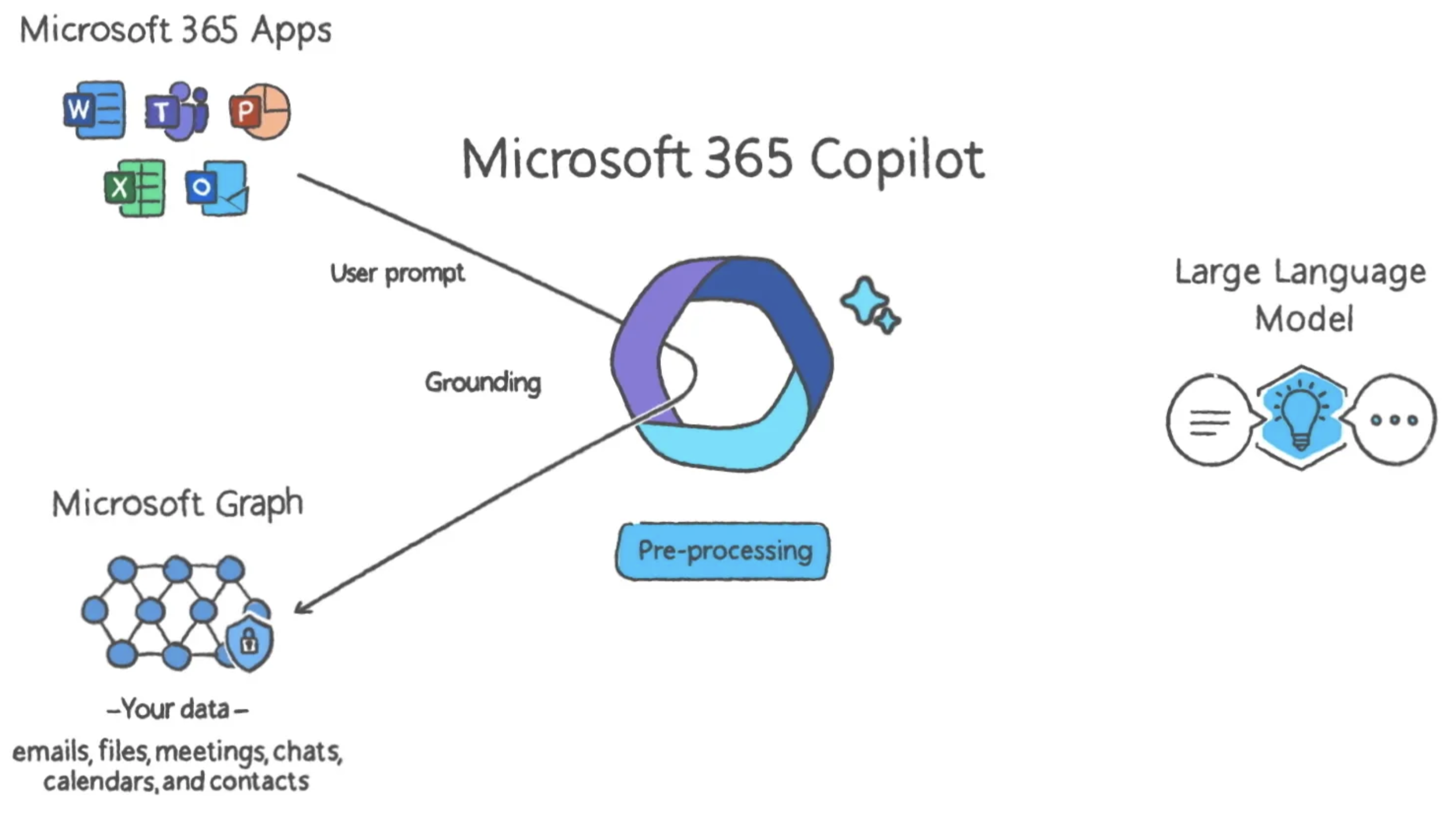
Can rough drafts be perfect?
With these 3 data sources you’re off to the races. The GenAI tool will use its powerful neural network to output what it thinks meets your needs best. Here is where the main expectation-setting comes in: you should treat any output as an initial, rough draft.
From conversations with developers (friends, colleagues, and customers alike), a common misconception I’m seeing is the immediate comparison between these tools and human developers.
As GitHub makes clear - tools like Copilot cannot replace development or the work developers do. It can only make existing developers more productive by outputting what should be considered rough drafts of code for them to get started with. The same applies to image generators and artists, writers and scripts, etc. You should not expect your first rough draft of an essay to be submission-ready. You should not expect an AI-generated rough draft to be perfect.
It would not be honest for an application to claim AI-generated content to be able to create content without human vetting, given the complexity and risk mentioned earlier. This is a tool in a human’s toolbelt today. There’s a reason GitHub named it Copilot and not Autopilot.
What it’s doing for me
As a worker, I therefore expect GenAI to be used to create rough drafts of the any final product I’m working on, with me going through that draft and making the necessary adjustments. When evaluating if any of these tools is useful to me then, the mathematical theory I’m trying to validate is:
Prompting + Suggestion Time + Vetting Time < Time to do it myself
If the sum of the time it takes for me to explain to the AI what I want it to do, the time it takes to process and respond, and the time it takes for me to vet the first draft is less than the time it takes me to do it myself - there is value. This is why I say GenAI tools are productivity tools first and foremost, the goal is to make you accomplish your goals faster.
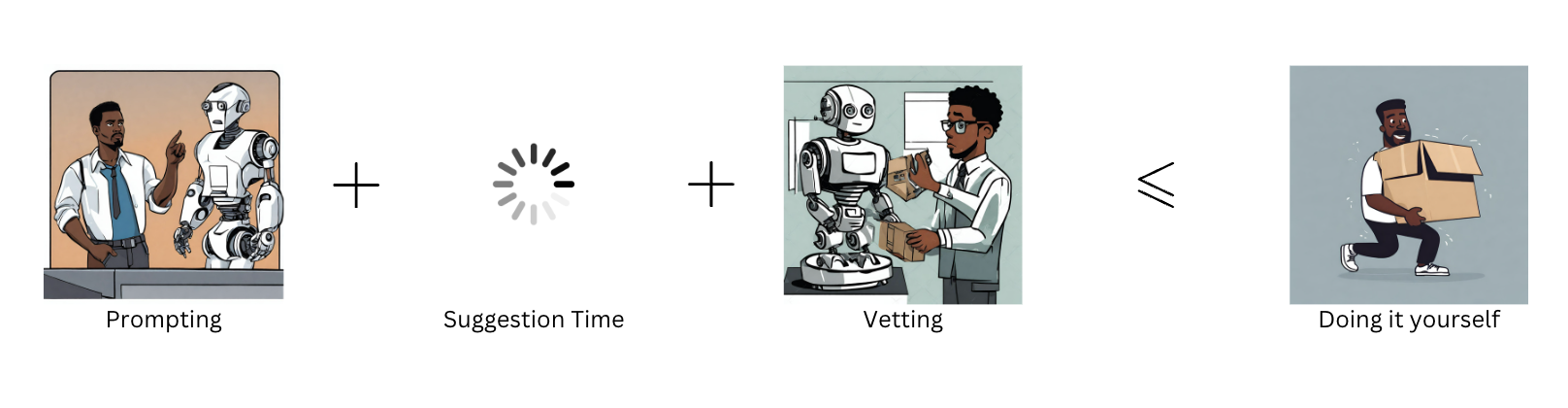
This is also the claim companies selling GenAI tools are making, and the evidence from research is more and more leaning towards this being true.
What you’ll find is that GenAI doesn’t have to be used everywhere and for all tasks. Certain tasks, like writing some tests for my newly created class, will see the above formula be true. Other cases, like just adding a line or 2 of SQL calls, might not make sense. The formula will have different results for different people, and that’s ok. What one person might use GenAI for, another person could feel it would be more efficient to create themselves.
As an individual, the main ramping you’ll have to do with these tools, aside from learning how to prompt them, is learning what use cases GenAI can actually help speed you up with.
Happy Accidents
GenAI can also have some side effects. For example tools like GitHub Copilot are being shown to help with code quality on top of productivity.
These side effects, in my opinion, arise from use cases with this application of AI. A large part of labor today has to do with creating content for our peers to consume (A report encompassing decisions we’ve made, code, artwork for a new character’s concept). A lot of labor is also understanding/distilling the content provided to us (issues a medical patient is reporting, code, a recorded meeting between colleagues) and making a decision based off of it. I grossly oversimplify by bucketing these into 2 groups:
- Content Generation
- Content Synthesis
As you can tell I like breaking things into categories :)
GenAI is still creating something new every time based on your prompt, and it helps with the productivity formula I showed earlier for both.
The improvements in things like code quality, though, come from the second bucket: Content Synthesis. If it takes less time for me to ask an AI tool how to best implement something, or what the summary of what I’m looking at does, it can make me a better ___ faster. GitHub Copilot can help me become a better developer faster, for example, by speeding up the synthesis of new information, leading me to write better code.
But even when synthesizing content I should be vetting. I may not need to if it’s low impact (e.g. Copilot explains to me how to initialize a VueJS project using the Vue CLI). But when it could be higher impact I may need to do it. For example, if ChatGPT is summarizing a report, I can read the summary provided, but still refer back to and skim portions of the document to make sure it’s not missing anything.
Again the use cases I’m referring to are code related due to where I work, but this can flow down to other industries as well. What if image generation tools (once they start being able to draw hands and shading correctly) allow me to become a better artist by learning 3D concepts and iterating on images faster?**
Conclusion
I think GenAI tools are here to stay, and will be used by more and more workers as they become more accessible. The main thing to keep in mind is that they are productivity tools, and should be treated as such. When evaluating such tools, remember that they do not have the full context today that you have over your task and what you need to do. They do not have your memory and learnings that help them make decisions.
Where does this lead us to? People have a lot of ideas but they’re just opinions as of now. Here are mine:
The easier access to AI is significant. It’s no longer a technology reserved for the tech-savvy or Amazon. Today, anyone can leverage the power of AI to enhance their work, learn new concepts, and iterate faster.
As we are able to feed these tools more context, and be more confident on the outputs, our relationship to how we generate and synthesize content will dramatically change. But that’s not for now. I’m likely going to give a more opinionated perspective on where I think we’re going in another post.
Thanks for reading.
*This is not to take away the impact of Recommendation Systems, which has been enormous and keeps affecting our societies today. You can read more about this in my more opinionated mini-blog on AI impacts (in the works).
**To be clear: Image generation tools are a little further away from being formally used in a professional setting. Reason being they suck, in my opinion. Read here on why developers are the first workers using AI tools first